Arpita Saha
Hi! I am a passionate Computer Science Researcher. My research work revolves around applying Machine Learning to build robust automated systems and perform knowledge discovery. Currently I am a Post-Masters Research Associate at Brandeis University, working with Dr. Subhadeep Sarkar at SSD Lab. Prior to that I was a Graduate Research Assistant working with Dr. Xia Ning at Ohio State. I received my Masters from The Ohio State University and my Bachelors from Bangladesh University of Engineering and Technology.
Experience
Research Associate
Graduate Research Assistant
Graduate Teaching Assistant
Lecturer
Education
The Ohio State University
GPA: 3.81/4.00
Thesis research on Machine Learning and AI in HealthInformatics: link
Bangladesh University of Engineering and Technology
GPA: 3.82/4.00
Research
Covid-19 Mortality Prediction and Patient Phenotyping from large-scale EHR data
ACM BCB 2023 (PAPER LINK)
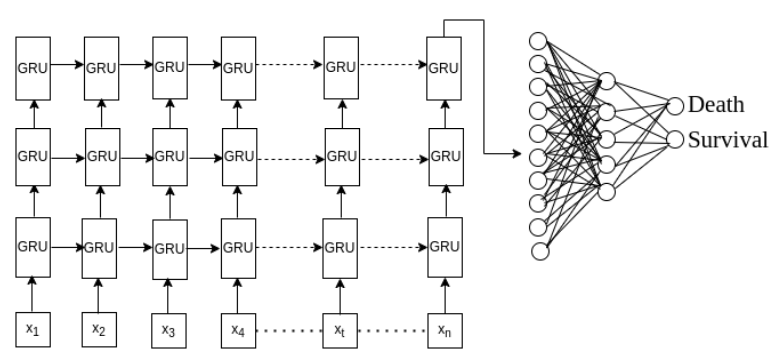
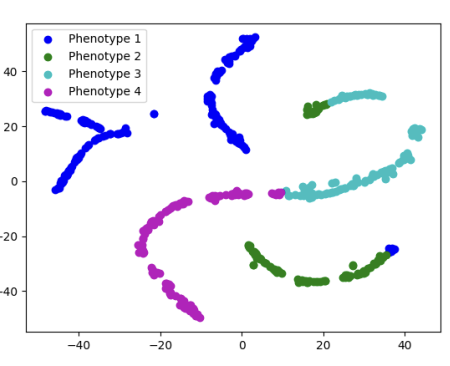
This work studies the relationship of patient data, such as demographics, lab results, comorbidities, etc. with disease outcomes and patient phenotyping. For this work we use large-scale Electronic Health Record data from the COVID-19 Research Data Commons (CoRDaCo). We built a GRU-based time-series deep learning model from scratch that obtained an AUC ROC score of 97% in predicting Covid-19 patient mortality from large-scale EHR data. Our model beats the SOTA accuracy on the same dataset using only 11K parameters compared to transformer models with subpar performance even with 700K parameters. We also investigated the strong expressive power of patient representation embeddings generated by our model by clustering them into distinct phenotypes and studying the trends of risk factors related to mortality across these phenotypes for efficient resource allocation during a pandemic. The project was published in ACM BCB 2023 as my first first-authored publication.
August 2022 - August 2023
KVBench: A Key-Value Benchmarking Suite
DBTest 2024 (ACM SIGMOD Workshop) (PAPER LINK)
This work aims to build a workload generator tool that can produce synthetic workload for NoSQL datasystems. It is integral to the stress testing NoSQL systems for correctness and performance benchmarking. This tool fills the gap between classical workload generators and complex real-life workloads by offering a richer array of knobs, such as the proportion of empty point queries, point and range deletes with selectivity specified, customized distributions for queries and updates, etc. Therefore this tool provides better support for emulating real-life workloads compared to the state-of-the key-value workload generators.
Performance Benchmarking of the various implementations of LSM Memory Buffer
In this project we are studying how the different data structure implementations of the LSM Memory Buffer affect the performance (latency and throughput) of NoSQL databases under varied workloads. Insert-only workloads benefit from an unsorted vector as the memtable, while skiplist performs better in the presence of point queries. So, we are implementing different data structures such as Unsorted Vector, Trie, Binary Search Tree, etc. studying the existing and new data structures to benchmark the optimal configuration of memtable for a given workload composition. We are using RocksDB open source NoSQL database for benchmarking and building our dataset as a prelude to the optimization problem.
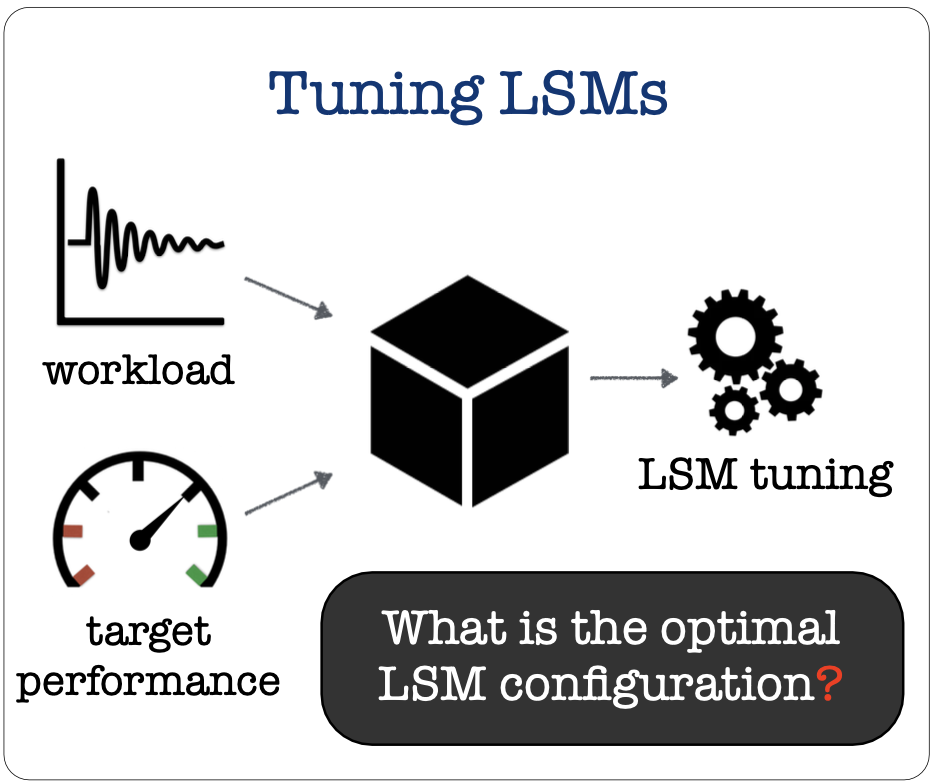
Toward Workload-Aware Self-Designing LSM Engines for NoSQL databases
NEDBDay 2024 (POSTER LINK)
In this research project, we aim to design ways to automate the tuning of LSM Tree data structure, the backbone of NoSQL Data Systems. NoSQL data systems have a multitude of exposed knobs that can be tuned to obtain the desired read write latencies and throughput performance. However, hand-tuning of these systems does not guarantee optimal configuration due to the vastness of the design space and complex interaction among knobs, hardware and workloads. Therefore, we leverage Machine Learning techniques to navigate through the vast design space of LSM Trees and learn the optimal combination of performance parameters or tuning knobs in response to dynamic workloads. By optimizing key performance metrics, we aim to make NoSQL data-systems more efficient and responsive to changing workload queries. The overarching goal of this research project is to use data-driven techniques to develop adaptive and efficient self-designing data-systems.
October 2023 - May 2024
QT-GILD: Quartet based gene tree imputation using deep learning improves phylogenomic analyses despite missing data
RECOMB 2022 (PAPER LINK)
In this project, we aimed to solve the Quartet Distribution Imputation problem in incomplete gene trees. We built a variational autoencoder-based semi-supervised appraoch empowered by NLP techniques such as masked language modeling and positional encoding, to impute missing taxa in incomplete gene trees. This helped improve SOTA of species tree estimation for better phylogenomic analyses. This work was published in RECOMB 2022 and later published in The Journal of Computational Biology.